

In onze vorige blog hebben we een introductie gegeven over wat Azure voor een platform is en het cloud-principe uitgelegd ten opzichte van on-premises. We gaven aan dat de mogelijkheden binnen Azure oneindig lijken, en dat is ook zo! Om even een paar Azure tools te noemen: data storage, dataverwerking, machine learning + AI, blockchain, Internet of Things, integratie van software en systemen, webhosting, compute (virtuele machines) en (web) apps. De gehele lijst vindt u hier.
Binnen Peacock werken wij veel met data en datatoepassingen. Bijvoorbeeld het opzetten van een data warehouse. Dit doen wij volgens het ETL-principe. In deze blog zoomen we in op een paar Azure data tools die nodig zijn in het ETL-proces en dan voornamelijk hoe Peacock dit ETL-proces aanvliegt.
ETL
ETL staat voor Extraction, Transformation and Load. ETL is het proces van hoe data worden geladen van één of meerdere bronsystemen naar een datawarehouse.
- Extraction: data ontsluiten uit één of meerdere bronsystemen (bijvoorbeeld Google Analytics & Salesforce);
- Transformation: het groeperen, opschonen en aggregeren van data en het leggen van relaties tussen de data;
- Load: de data komt in een datamodel (of datawarehouse) ter voorbereiding voor visualisatie.
Binnen Azure lost u het ETL-proces op verschillende manieren op, bijvoorbeeld in de end-to-end totaaloplossing Synapse Analytics, maar daarover in de volgende blog meer.
Azure data tools
Naast de end-to-end oplossing is het ook mogelijk om met losstaande data tools het ETL-proces in te richten. Er zijn meerdere wegen die naar Rome leiden. Op de vraag wat de beste oplossing is, is niet echt een eenduidig antwoord te geven. Dit heeft te maken met verschillende aspecten en voorkeuren (met welke toepassingen en in welke programmeertaal wilt de developer de oplossing ontwikkelen). Microsoft biedt zelf een best-practice met data factory voor het ontsluiten van bronnen en databricks voor het transformeren van de data. De uitkomsten worden weggeschreven in een data lake en een SQL-database.
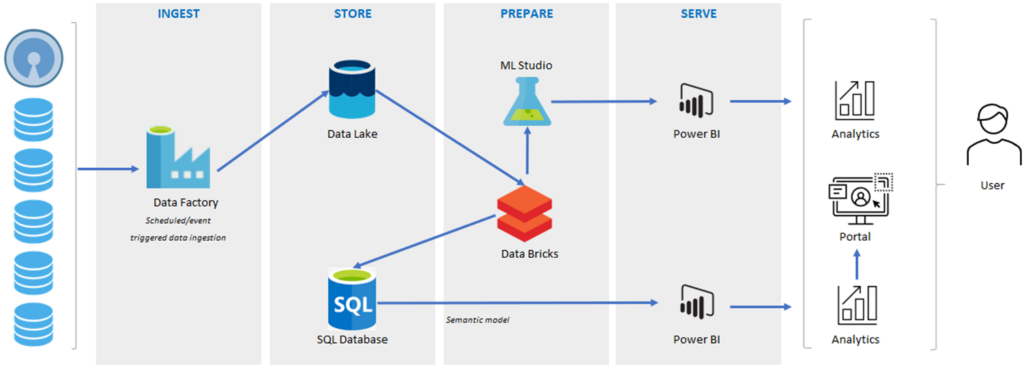
Wat u hier ziet is het ETL-proces. Dit bestaat uit Ingest, Store, Prepare en Serve. Eerst worden de data opgehaald uit data factory en opgeslagen in de data lake. Vervolgens worden de data getransformeerd in databricks en gestructureerd opgeslagen in bijvoorbeeld een SQL-database. Vanuit deze database worden de data aangeboden in Power BI of Analysis Services in een (semantisch) datamodel. Hierin zijn de relaties tussen verschillende tabellen bepaald en worden rekenwaarden gemaakt om snel en interactief dwarsdoorsneden van de data te maken. Op dit datamodel worden verschillende rapporten of dashboards ontwikkeld in visualisatie-tools zoals Power BI.
Hieronder geven we meer uitleg over functionaliteiten binnen deze verschillende data tools
Data factory
Een tool waarmee data uit verschillende systemen worden gehaald. Er zijn ongeveer 150 bronnen waar deze tool een standaard koppeling mee heeft. Bijvoorbeeld met SalesForce, Dynamics, SAP, SharePoint, Oracle, Google, Amazon en vele anderen. Hierdoor kunt u zonder code in een intuïtieve omgeving ETL-processen ontwikkelen. Indien de automatische koppeling niet aanwezig is, is er de flexibiliteit om dit zelf te programmeren.
Data lake
Een grote storage waar alle data, gestructureerd of ongestructureerd worden opgeslagen. Dit kan in containers, file shares of tabellen. Microsoft biedt hier een oneindige opslag aan. Dit betekent dat u alleen betaalt voor wat u per maand hebt opgeslagen. Data lake storage biedt de mogelijkheid voor beveiliging op bestandsniveau en een gelaagde opslag met mogelijkheden tot hoge beschikbaarheid en herstel na een noodgeval. Voor het data lake zijn er verschillende toegangsniveaus beschikbaar;
- Hot: data worden veel gebruikt en verandert vaak.
- Cool: data worden soms gebruikt, maar wel voor ten minste 30 dagen opgeslagen.
- Archive: data worden bijna nooit gebruikt, maar wel voor tenminste 180 dagen opgeslagen en is pas na uren beschikbaar.
Uiteraard zijn de cool en archive storage goedkoper in gebruik dan de hot storage.
Databricks
Een open source platform voor het transformeren van data. Bijvoorbeeld in notebooks. Dit is een script waarin u verschillende programmeertalen gebruikt, zoals Python, Scala, Java en SQL, het voordeel is dat u binnen één notebook verschillende talen combineert. Databricks slaat geen data op, maar de data ‘stroomt’ er doorheen. Daarom kiezen wij ervoor om de getransformeerde data op te slaan in een SQL-database.
SQL-database
In de SQL-database worden gestructureerde, opgeschoonde en bewerkte data opgeslagen in een tabelvorm structuur. De data worden gestructureerd opgeslagen zodat het altijd in de juiste format beschikbaar is voor de eindgebruiker. Azure SQL-database is een schaalbare relationele database service geoptimaliseerd voor goede prestaties. Het ophalen en verwerken van data zijn twee aparte processen. In de tussentijd moet de data ergens (tijdelijk) bewaard worden. Data lake is in die zin een doorgeefluik tussen deze tools.
Een datamodel in Power BI of in Azure Analyses Services leest de tabellen uit SQL-database in en bepaalt hiertussen de relaties, zodat u uw dashboard en rapportages kunt ontwikkelen. Natuurlijk zijn andere visualisatietools ook mogelijk.
Toekomst ETL-proces?
De toekomst is er nu al; Azure Synapse Analytics. Dit is een end-to-end datawarehouse oplossing, waarbinnen het gehele ETL-proces wordt vormgegeven. Alle hierboven genoemde technieken zijn in een standaard analyse service geïntegreerd, zodat u zelf de vrijheid heeft om gemakkelijk gegevens op te nemen, te verkennen, voor te bereiden, te beheren en te leveren voor BI- en machine learning-behoeften. In onze volgende blog gaan we hier dieper op in.

